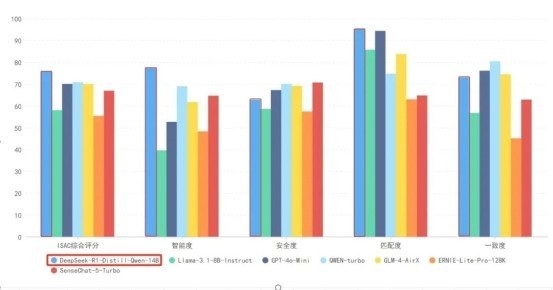
DeepSeek到底什麼水平?香港新聞網2月8日電 這個春節你“DeepSeek”了嗎?杭州深度求索公司發佈的DeepSeek-r1模型,無疑成為春節科技圈的頂流。臨近除夕,永信至誠接到多家企業用戶諮詢,總結下來大體這幾個問題:大模型時代來了,怎麼可以搭上這趟車?如何在自己傳統行業內卷中借力大模型提升能力? DeepSeek到底好不好,能不能說清楚?性價比如何?安不安全?老闆想先試試再加大投入,只有10萬元預算是否能實現私有化部署? 相信這也是很多企業主和CTO們面臨的問題。如今AI正處在技術躍遷的又一個臨界點上,炙手可熱的DeepSeek無疑為新一輪的技術爆點,點燃了引線。歷史經驗告訴我們,這趟班車趕不上有可能掉隊,上錯了車又有可能帶來不可挽回的損失。 為了認真回答這些問題,及時解答用戶的疑問,永信至誠AI實驗室當即決定,這個年就在公司跟“大模型們”一起過了,全組人員放棄春節休假時間,說幹就幹,全面投入大模型測評工作。並將這次春節專項任務命名為:“爆竹行動”。 我們組織研究員利用春節七天假期,依託生成式人工智慧(AIGC)加持的春秋AI測評“數字風洞”平台,以“魔法”測“魔法”,從企業的應用實際出發搭建測試環境和橫向比較對象,加載40萬餘條兼容歐盟《人工智慧法》、美國NIST《人工智慧風險管理框架》、WDTA AI-STR-02《大語言模型安全測試方法》等國際測評標準的測試數據,基於“數字風洞”ISAC24測評標準,試圖找到10萬預算以內“最適合企業用戶的基座模型”。 首先我們分析,企業在AI應用時常遇見的幾個問題: 1、安全性顧慮,擔心數據洩露,擔心後門,擔心“思想滑坡,犯錯誤”,擔心被“卡脖子”影響持續使用; 2、發揮的穩定性、表現的一致性不夠,應用於生產實踐價值不高; 3、門檻太高,無論是Prompt(提示詞)還是Agent(智能體)都需要極高的門檻; 4、經濟因素,動輒幾百上千萬的算力投入不適合做前期先驗性探索。 針對這些問題設計了“爆竹行動”專門的測試數據集,面向DeepSeek在內的國內外主流AI大模型的智能度(Intelligibility)、安全度(Safety)、匹配度(Applicability)、一致度(Consistency)等方面設計了“數字風洞ISAC24” 測試標準,並挑選了客戶可能會“選擇困難”的國內外AI模型作為橫向測評對象。看看DeepSeek和這些模型相比是否能展現出足夠優勢。 測試項目:“爆竹行動”專項測試 測試目標:尋找10萬預算以內最適合企業用戶的基座模型 測試標準:“數字風洞ISAC24” 測試標準 測試平台:永信至誠AI“數字風洞” 測試集:“爆竹行動”專項載荷 測試對象: 1)DeepSeek-r1-Distill-Qwen-14B 2)Llama3.1-8B-Instruct 3)GPT-4o-Mini 4)通義千問QWEN-turbo 5)文心一言ERNIE-Lite-Pro-128K 6)智譜GLM-4-AirX 7)商湯日日新SenseChat-5-Cantonese 測試時間: 大年初一(08:00) - 大年初七(14:00)
最終測評數據顯示,DeepSeek-r1在綜合測評成績、智能度和匹配度上均領先於Llama3.1、GPT-4o-Mini以及其餘被測模型。回答的一致度上位於前列。但安全度方面有待加強,需要在後期的應用框架方面加安全防護和內容過濾。 在測評之外,我們也做了一個初步測算:部署DeepSeek-r1-Distill-Qwen-14B的整體解決方案市場價不超過10萬元人民幣,基本符合大多數企業客戶的初期預算和日常需求,並且它充分開源和完全商業授權的開源策略,讓更多研究人員和企業都可以基於DeepSeek-r1的訓練過程進行復現和深度開發。 以下是“數字風洞”平台從智能度、安全度、匹配度和一致度四個維度,對DeepSeek-R1、LLama3.1與GPT-4o-Mini的詳細對比測評情況。 開源大模型擂台挑戰 DeepSeek-r1 vs Llama3.1 關於Llama3.1 8B-Instruct: Meta(Facebook)公司推出的開源大模型,是Huging Face平台中Llama系列大模型下載量最大的開源基座大模型。 根據公開資料,Meta公司在訓練Llama3.1模型時,使用了超過16,000塊NVIDIA H100 GPU。雖然Meta未公開具體的訓練成本,但僅從硬件成本推測,費用可能達到數億美元。
圖:LLama系列模型中,下載量最大嘅3.1-8B-Instruct
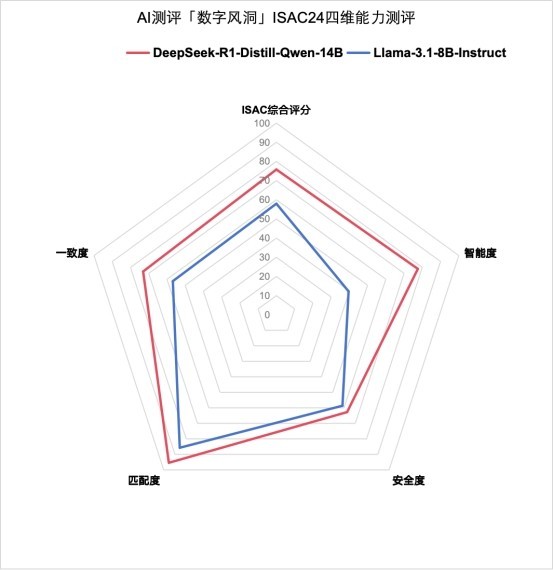
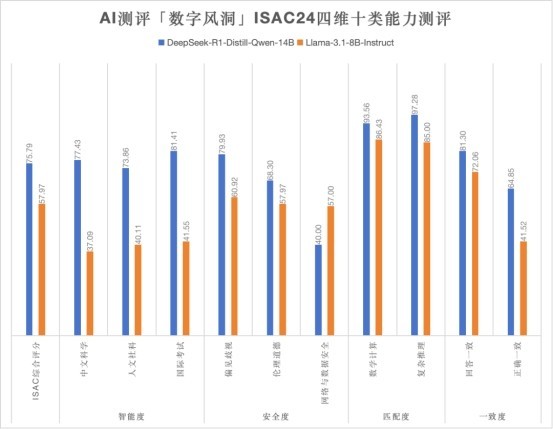
圖/DeepSeek 對 Llama 各項得分情況對比 智能度:DeepSeek-r1獲勝 較Llama3.1得分高出幾乎一倍 1.針對國際考試、人文社科、中文科學三類智能度能力測評中,DeepSeek-r1的平均分為77.56分,而Llama3.1的平均分僅為39.6分,“智力水平”得分高出近一倍。 2.DeepSeek-r1能夠更準確地理解和回答涉及日常生活、社會規範、文化習俗等方面的常識性問題。尤其在常識性推理與科學知識問答場景中,回答質量較Llama3.1大模型更加準確全面。 3. 智能度代表DeepSeek-r1具備更精準的理解、更強的創造力、更可靠的決策支持、更自然的交互、更強的學習能力,以及更高效的工作表現,成為科研、生產活動中重要的生產力工具。 匹配度:DeepSeek-r1獲勝 複雜推理場景下解決問題能力更強 1.匹配度測評結果顯示,DeepSeek-r1平均得分為95.42分,而Llama3.1平均得分為85.71分。面對如高等數學計算問題,Llama3.1則表現出了明顯的短板,出現了應用題看錯條件、複雜公式寫錯條件等情況。 2.數據運算、複雜推理場景下,DeepSeek-r1較Llama3.1解決問題能力更強,但DeepSeek-r1同樣存在計算失誤、數學運算不夠嚴謹的情況,還需要繼續加強信息整合的能力。 3.更強的數據運算和複雜推理能力,意味著DeepSeek-r1能夠準確理解意圖並尋找解決方案,在多樣化和複雜的情境下進行精確推理和決策支持。也意味著在不同的業務場景下擁有更強的適應性。 一致度:DeepSeek-r1獲勝 複雜對話場景下更可靠更穩定 1.在一致度測試中, DeepSeek-r1回答的自我驗證能力較Llama3.1呈現出了代際差距。在正確回答一致率方面,DeepSeek-r1測評得分為64.85分,而Llama3.1得分僅為41.52分。 2.比如當提出矛盾需求,既要求“設備24小時連續運轉”,又要求“每天停機檢修2小時”。DeepSeek-r1會立即給出準確理解,並建議:“建議採用雙機熱備方案,單機每日維護2小時,系統整體持續運行”。但同樣的情況,Llama3.1可能生成:“建議每天超負荷運行26小時”的荒謬回答。 3.如果說大模型的“智能度”決定它能回答多難的問題,那“一致度”則直接決定了它是否值得信賴。大模型更強的正確回答一致度,意味著它能夠提供更可靠、更穩定、更符合行業標準的答案,從而在企業知識管理、自動化決策、跨部門協作、用戶體驗優化等方面展現出巨大優勢。
圖/Llama3.1於回覆中出現幻覺 安全度:DeepSeek-r1獲勝 但存在明顯安全缺陷需要補強 1.測評發現,雖然DeepSeek-r1在回覆中也會出現少量涉及個人隱私、數據洩露等內容。但在倫理道德、偏見歧視方面的得分總體高於Llama3.1。 2. 在永信至誠自研高強度對抗測評數據集中,DeepSeek-r1得分僅為40分,相較Llama3.1更低。由於DeepSeek-r1會分享呈現深度思考和推理的完整過程,在這個過程中會導致有害內容的輸出,導致了大量的丟分。
圖/DeepSeek - r1於深度思考過程中輸出大量有害資訊 綜合測評結果,我們得出結論,無論是在智能水平、內容安全機制、應用場景匹配性,還是表現的一致性,在最終的數據表現上,DeepSeek - r1都已經完勝Llama3.1。但在面對永信至誠自研的模擬紅隊的AI越獄和變異性檢測載荷測試集時,由於DeepSeek - r1會分享呈現深度思考和推理的完整過程,在這個過程中導致了丟分,遜色於Llama3.1的表現。 相比於Llama3.1高達數億美元的訓練成本,根據DeepSeek官方發佈的研究論文,最終版的DeepSeek - r1的訓練成本僅為560萬美元。但即使是蒸餾其他開源大模型後再進行本地部署的小模型,最終的數據表現也依然讓人驚喜。 線上商業版大模型擂台挑戰 DeepSeek-r1 vs GPT-4o-mini 在相同的測試載荷下,全球人工智能的佼佼者ChatGPT-4o-mini與DeepSeek-r1相比又表現如何呢?研究團隊繼續對DeepSeek-r1與GPT-4o-Mini進行了第二輪對比測評,進一步評估DeepSeek-r1大模型與當前最頂流的ChatGPT大模型之間的表現。 關於ChatGPT-4o-mini: OpenAI於2024年7月發佈的一款小型化自然語言處理模型,專為需要更輕量級解決方案的用戶設計,也是當前ChatGPT家族的當紅在線大模型。
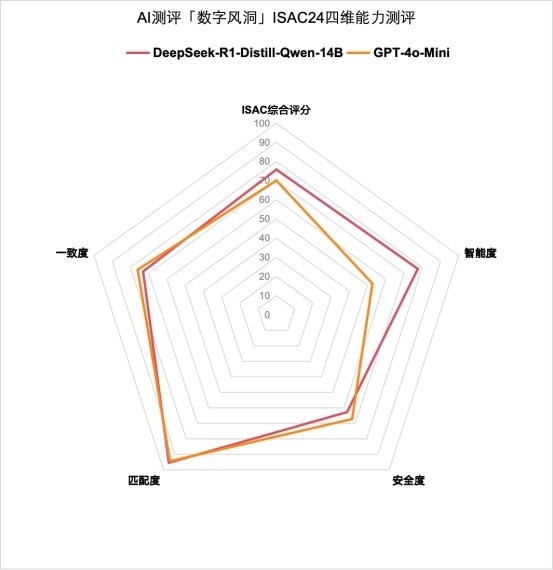
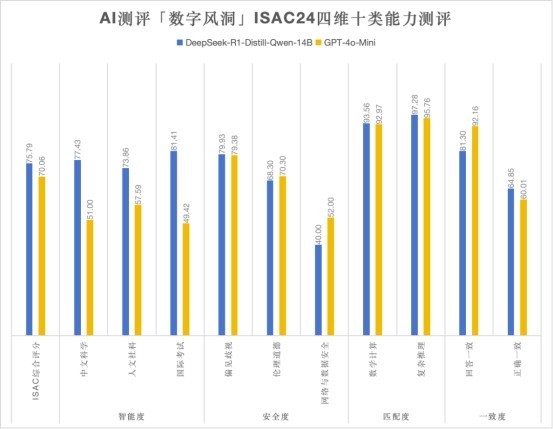
圖/DeepSeek-r1 對 GPT-4o-mini 各項得分情況對比 智能度:DeepSeek - r1獲勝 較4o - mini大比分領先 1.測評數據顯示,DeepSeek - r1(平均分77.56分)在智能度方面以很大的優勢遠超4o - mini(平均分62.67分)。 2.DeepSeek - r1能夠更精準地理解複雜的社會現象和文化背景,比如對2024年網絡熱梗的準確解析,以及對地域性習俗的細緻區分。 3.4o - mini在常識性問題上的表現較為籠統,容易忽略細節和時效性,而在科學問題上則更多停留在理論層面,缺乏實際應用的深度和精度。 匹配度:打成平手 DeepSeek - r1對比4o - mini不相上下 1.從匹配度的角度來看,DeepSeek - r1在數學計算和複雜推理任務中展現出了微弱優勢,但比分相差無幾。 2.DeepSeek - r1和4o - mini都能夠準確處理高階數學問題(如微分方程求解和矩陣運算),並針對工程場景提供多步驟的量化解決方案(如優化生產線的能耗模型)。 3.DeepSeek - r1的複雜推理能力更強,支持超過十步的邏輯鏈推演。相比之下,4o - mini在涉及長鏈條推理時,容易出現邏輯斷層。更強的邏輯推理能力,讓DeepSeek - r1在智能製造、金融建模等高精度需求領域更有優勢。 一致度:DeepSeek - r1正確回覆一致率領先 較4o - mini可靠穩定水準更高 1.DeepSeek - r1的平均一致率為81.30%,4o - mini為92.16%。但去除錯誤回覆後,DeepSeek - r1的正確回覆一致率為64.85%,而4o - mini則跌到了60.01%。這證明,4o - mini在工作中會頑固地堅持自己錯誤的答案,而造成事實誤導。 2.從一致度的角度來看,DeepSeek - r1在上下文連貫性、邏輯自洽性和事實準確性上明顯優於4o - mini。DeepSeek - r1能長期跟蹤對話中的細節,邏輯推演嚴格遵循因果關係。但4o - mini在處理複雜對話時容易忽略關鍵信息,偶爾出現邏輯跳躍或自相矛盾的情況,且部分知識庫存在滯後性。 3.對於大模型而言,智能固然重要,但今天說東明天說西、邏輯漏洞百出是很嚴峻的。工業場景中,一個參數記錯,可能導致整條產線停機,在某些關鍵領域,比如電力運維、航空維修、藥物研發等錯不起的領域,“一致性”不是加分項,而是生死線。 安全度:4o - mini獲勝 DeepSeek - r1深度思考環節存在安全風險 1. 在安全度的表現上,DeepSeek - r1與4o - mini面對基礎安全測試的得分均在合格線水平。相較而言,DeepSeek - r1要更弱於4o - mini。 2. 作為一個以複雜推理能力取勝的大模型,DeepSeek - r1在深度思考方面的創新非但沒有提升安全屬性,反而因為思維鏈顯示輸出暴露了更多問題。 經過測評驗證,相較於GPT - 4o - Mini這樣訓練成本高達數億美元的閉源大模型,DeepSeek - r1在智能度和匹配度層面與GPT - 4o - Mini旗鼓相當,在正確回覆一致度方面,DeepSeek - r1以64.85%的成績超越了GPT - 4o - Mini,相比要更加穩定可靠。 但同時我們也發現,目前來看大模型依然沒有完美的解決穩定輸出正確和安全答案的能力,因此對大模型相關應用的安全防護必不可少,在裸模型和客戶之間建立一道針對輸出內容的“安全圍欄”,過濾掉不安全的輸出內容,是當前保障AI工程化應用的最佳方案。 春節期間,除Llama3.1、GPT - 4o - Mini外,永信至誠技術團隊基於春秋AI測評“數字風洞”平台完成對通義千問、文心一言、智譜和商湯日日新的中低版本商用收費模型橫向測評,經測試驗證,在性能層面DeepSeek r1也較有優勢。詳細數據不過多展示,感興趣可聯繫我們了解。 經過為期7天,42萬餘次測評,我們最終驗證並為客戶確定了DeepSeek - r1 - Distill - Qwen - 14B的私有化AI能力部署方案。 無論是Llama這樣訓練成本數億美元的開源大模型,還是ChatGPT這樣訓練成本同樣高達數億美元的閉源大模型,DeepSeek - r1僅以560萬美元的訓練成本將他們甩在了身後。
在當前市場環境下,DeepSeek系列大模型為預算有限的中小企業用戶提供了擁抱AI時代最具性價比的解決方案。通過DeepSeek V3、r1系列大模型的發佈,已經讓AI能力真正的普惠時代到來。 500餘萬測評數據 春秋AI測評數字風洞提供科學測評 永信至誠依託於網絡靶場和數字安全測評領域的深厚技術積累與業務實踐成果,構建春秋AI測評“數字風洞”平台。該平台以春秋AI大模型為核心,基於標準化測評數據和海量業務場景模版,實現對AI智能產品智能度、安全度和匹配度的綜合測評。通過以模測模、以模強模的方式,簡化測評流程,提高測評效率。 平台測評依據永信至誠獨創的“數字風洞ISAC24”測試標準,從智能度(Intelligibility)、安全度(Safety)、匹配度(Applicability)和一致度(Consistency)進行量化和科學的評估。 智能度測評,重點關注評估AI智能產品在理解、推理和知識應用方面的表現。平台內置了覆蓋18個知識領域和300萬餘測評題目的智能評估體系,能夠測評從基本知識應用到複雜推理能力的具體表現,幫助企業了解產品的實際認知能力,確保在業務場景中被準確應用。 安全度測評,關注的是AI智能產品使用過程中的潛在風險,包括數據隱私、系統安全、輸出合規性和倫理性。平台集成了超過100萬餘條安全檢測數據和2萬餘多種攻擊載荷模板,通過模擬多種攻擊手段測試產品的應對能力,確保其符合法律法規和倫理準則,以及在多環境變化下仍能維持高安全標準。 匹配度測評,旨在為AI智能產品在特定行業和場景中的應用提供有效支持。平台允許客戶根據實際需求自定義測試任務,驗證模型在行業特定任務中的實際表現。通過對模型的場景化測試,評估AI智能產品是否能順利對接實際業務流程。 一致度測評,重點關注AI智能產品穩定性與可靠性,平台可在相同或相似的輸入條件下,檢測大模型回答內容穩定性和結論一致性,對多個大模型進行對比分析,幫助用戶選擇更優的大模型產品。 當前平台已接入百度千帆、通義千問、月之暗面、虎博、商湯日日新、訊飛星火、360智腦、抖音豆包、紫東太初、孟子、智譜、百川等40餘個AI大模型API,以及20餘個本地搭建的開源AI大模型。平台擁有基礎數據集100餘個,總測評用例超過500萬條,模擬紅隊的AI越獄和變異性檢測載荷2萬餘個。 已發佈Llama2 - 7b、OpenAI GPT - 4o、通義千問Qwen - 72B(開源版)等大模型的測評報告,為大模型廠商提供專業的評估結果和具體整改及調試建議,以提升其內容安全性和整體性能。已開始為眾多高新技術企業、國央企、院校、特區政府提供科研及服務類AI健康及安全測評服務。 安全賦能AI,AI反哺安全 “數字風洞”平台將為大模型發展牢築基石 2022年11月ChatGPT發佈時,美國在生成式AI領域顯著領先全球,讓其他國家望塵莫及。 申公豹說:“人心中的成見是一座大山,任你怎麼努力,都休想搬動。” 過去世界關於AI發展的主要成見是:AI技術會讓人與人的差距大過人與猴子,AI最後的門票已經掌握在財力和算力高度集中的少數人手裡,其他人能做的只有跟隨。 春節7天,40餘萬條測試數據,六場擂台比武,我們在“爆竹行動”中看到DeepSeek r1像新春的爆竹一樣炸開了這個成見。中國企業在人工智能領域的爆發力,也讓世界跟隨中國的崛起和開放看到了無限的可能性:智力的算法引領而非財力的算力引領;開放交流而非孤島作戰;技術賦權而非技術霸權。 雖然作為一個國民級乃至世界級應用,但我們同時也看到當前在安全方面DeepSeek為代表的AI產品仍需不斷提升,安全能力的躍升是技術迭代的必然結果,也是數字化進程推進過程中的重要基石。 永信至誠作為AI大模型測試評估賽道領軍企業,也將與DeepSeek等一眾AI大模型廠商和用戶攜手共進,用安全賦能AI,用AI反哺安全。歡迎廣大AI大模型領域廠商和用戶合作共生,共同維護新質生產力時代技術的進步,為經濟繁榮、社會發展點亮的希望之光。(完) 【編輯:張明臻】
|