推理模型評測報告:文心X1 Turbo領跑中國國內總分第一分享到:
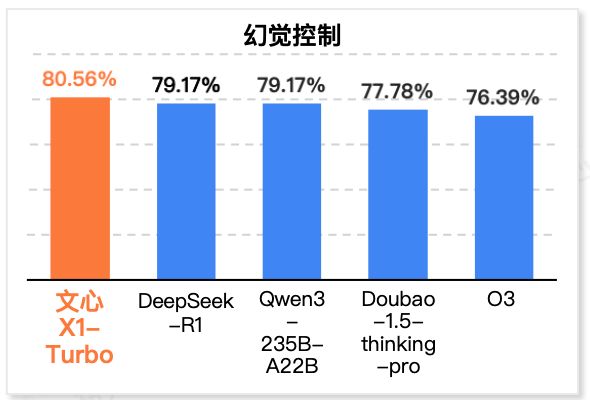
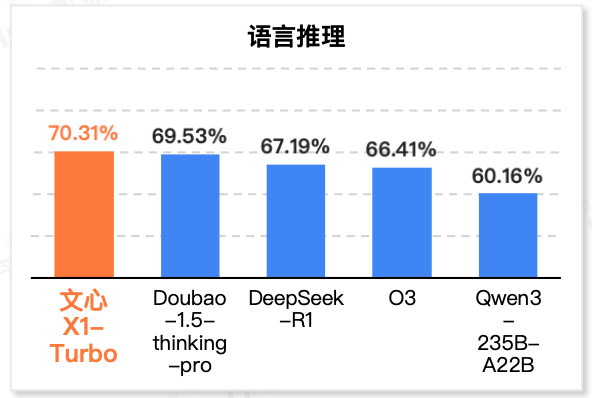
香港新聞網5月29日電 5月29日,極客邦科技雙數研究院InfoQ研究中心正式發布《2025推理模型評測報告》,基於邏輯推理、數學推理、多步推理、語言推理、及幻覺控制五大維度,對OpenAI O3、文心X1 Turbo、DeepSeek-R1、Kimi k1.5、Doubao-1.5-thinking-pro、Qwen3-235B-A22B等八款中國國內外主流推理模型展開深度評估。報告顯示,文心X1 Turbo以總分第一的成績領跑國內模型,並在幻覺控制、語言推理等核心維度展現顯著優勢,成為國內首個在五大評測維度中斬獲最多單項冠軍的推理模型。 InfoQ研究中心指出,受“推理時計算拓展”與“可驗證獎勵強化學習”兩大技術範式驅動,全球廠商已進入推理模型密集發布期,OpenAI o1、DeepSeek R1、 文心 X1 Turbo、Claude 3.7 Sonnet Reasoning等十餘款推理模型相繼上線,爭奪下一代大模型的“推理入場券”。 根據報告,文心X1 Turbo是本次評測中“單項冠軍數量最多”的模型,在五大細分維度中表現亮眼:在幻覺控制方面,文心X1 Turbo以80.56%的得分位列第一,領先DeepSeek-R1、Qwen3-235B-A22B等模型,有效降低模型生成錯誤或誤導性信息的風險;在語言推理方面,文心X1 Turbo以70.31%的得分位列第一,領先Doubao-1.5-thinking-pro、DeepSeek-R1、Qwen3-235B-A22B等模型;在數學推理方面,OpenAI O3以81.25%的得分位列第一,文心X1 Turbo緊跟其後,位居國內第一。
幻覺控制Top 5模型得分情況
語言推理Top 5模型得分情況 報告認為,作為國產推理模型代表,文心X1 Turbo其技術突破不僅標誌著國產模型在推理能力上的里程碑式進展,更為AI從“內容生成”向“可驗證邏輯執行”的躍遷提供了關鍵支撐。 隨著技術迭代與場景深化,推理模型把大模型從單純的內容生成器升級為“可驗證的邏輯執行器”。伴隨著單場景推理深度、跨工具編排廣度、在線自進化能力的同步躍升,更多新商業機會正被快速打開。(完) 【編輯:黎金良】
相關新聞 |
視頻更 多
大型雜技劇《唐古百戲》登香港 舞台重現大唐風采觀眾大讚:滿滿視覺享受!
組團參加少年太空人體驗營 香港中學生:最期待去酒泉衛星發射中心
36屆香港書展正式開幕 黃雨下觀眾依舊大排長龍
【通說環球】海上張網“抓”箭!中國火箭回收“不走尋常路”
“南海仲裁案裁決”被炒作 吳士存:不讓裁決書壽終正寢,南海就永無寧日
“環顧四周,很多國家都不安全,反而香港在各方面都比較安全”
【你不知道的香港】輪椅也能上天星小輪?殘障人士:香港無障礙設施不輸任何地方
來論更 多評論更 多
論壇更 多閱讀排行
|